
Using custom logs in Log Analytics is a surprisingly easy thing to do. It can be fun, but of course ultimately used for business related purposes. You can use a Logic Apps to submit, PowerShell or Azure Functions as well. Ultimately any language that can make a REST call and format JSON can submit to the API. In this post I’ll give some best practices when designing your custom application logs. So operations people, pass this along to your app dev people.
Data Consistency
When you submit a custom log to the Log Analytics API, the log is ingested and examined. During the examination all fields are given a data type, string fields are given an _s and doubles are given _d and so on. Your log payload must be the same, every. single. time. I cannot stress this enough. That means case sensitivity on each column name, and the data type in each field. Lets examine my BBQ log I linked to above for a minute. The food temp field Food1_Temp_d is a double. However if I submit the field as a string, an entirely new field Food1_Temp_s is going to be added to my log, and every log thereafter, even if I revert back to submitting the field as a double. The same is true for case sensitivity. Food1_Temp_d is not the same field as food1_Temp_d.
Your code or app may see:
Food1_Temp_s
Food1_Temp_d
food1_Temp_d
Food1_Temp_d
as all the same. But I assure you Log Analytics does not.
I don’t care how you submit your logs to Log Analytics or with what code base, but your data must be consistent. Developers, you may not care about data consistency in your logs, but Log Analytics does. If you’re data isn’t consistent, you will have a hard time down the road when your app breaks, read: it will break at some point, and you want to find out why.
Logs for Microservices Architecture
For your standard monolithic application, logs are relatively easy. You may have one or two custom logs and thats all you need. However, microservices are all the rage, for a number of reasons I won’t be going into here. But designing custom application logs for microservices presents a few challenges.
Here is a microservices diagram borrowed with pride from Microsoft docs.

From that same doc comes a challenges section, specifically about logging:
Management. To be successful with microservices requires a mature DevOps culture. Correlated logging across services can be challenging. Typically, logging must correlate multiple service calls for a single user operation.
So how do you log across services when Service A may be used by Application A or B but not C? One option is to have a custom log per service. This could get cumbersome with tens or hundreds of services. Another option would be to dump all logs into one custom log. This would not be my preferred method for a few reasons. One, custom logs in Log Analytics support up to 500 columns. Eventually your going to run out of columns, however having more than 30 or 40 columns in a log is cumbersome. Two, this also leads to having to filter through more data to find what you need. If you’ve ever used the AzureDiagnostics log you know exactly what I’m talking about. It is not surprising to me that Microsoft has started separating the Azure Diagnostic logs to their own resource specific logs.
My recommended way to custom log a microservices architecture would be to have 1 custom log per application. No matter what services the applications used you would have one log for that app and each service could potentially submit logs under multiple application logs. See this example spreadsheet for visualization.
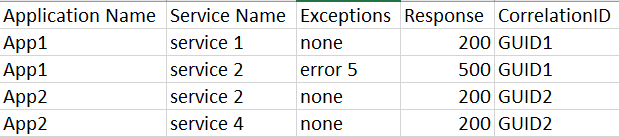
So App1 would have a custom log of App1_CL and App2 would have App2_Cl where services 1 and 2 could have logs under App1_CL and Services 2 and 4 could submit logs under App2. Essentially whatever overarching application calls a service, would then send a log for that service under its application name. The CorrelationID GUID would change for each new transaction as well. This would allow you to filter down to all logs that that GUID.
There are a few reasons to do separate logs per application. As I mentioned above, I only want information relevant to what I’m looking for. Having multiple applications under one log, while not a big deal to filter adds an extra step and extra data to parse and does add extra fields if the logs have different columns. Another is for Table level RBAC, while you cannot assign specific RBAC to individual custom logs currently, I suspect that this is coming at some point. So if application owners for app 1 shouldn’t see logs from app 2 then you could set the RBAC for that and vice versa.
General Recommendations
The cost of Custom Logs can actually be quite cost effective. This is another reason why you want to more carefully consider your custom application logging. If you design it properly, not only can you log be effective monitoring tool, it could be extremely inexpensive. Just collecting everything and packaging that into JSON and sending to Log Analytics is not a good custom log design.
Don’t send the same value in multiple fields, for one, this seems really redundant. But as the person designing log queries, dashboards and alerts, its rather annoying not knowing why the same value is coming in, in different fields. And sometimes its in one of the fields, but not another.
Try not to send nested fields. Though if you have to send a nested field, at the very least make sure its a JSON field. Its much easier in my experience to separate out those fields, than to separate out XML fields. Or send a rendered message field from the XML in the log.