
What a difference 3 years makes. Since my last Extracting nested fields post, I’ve learned a lot and thought it might be time to provide a new post with new examples and more ways to accomplish the same goal. Like the first version, but better!
Operators, Functions & Dynamic Types, Oh my!
There are a number of operators & functions to know when you approach a nested object. The first to know are the Parse operators. We need the parse operators to cast columns to a dynamic type.
- parse_json
- todynamic
- parse_xml
Parse JSON and To Dynamic are synonyms, which means they do the same thing. Up until the exact moment of writing this I preferred using todynamic, for the explicit reason as its very clear on what it exactly its doing. Both Parse JSON and To Dynamic cast the column you provide it to a dynamic type. For some reason, some fields as they’re ingested into Kusto, are not set as a dynamic type, and are strings, or another type. When we want to extract any data from these columns, and its not a dynamic type, you’ll get an error stating the column is not of dynamic type. And that is the exact reason why I prefer To Dynamic. When I read “parse json” I expect something similar to evaluate bag_unpack, which I’ll cover later.
Parse XML takes the XML column, converts it to JSON and casts it as a dynamic type.
The rest to know that are relevant to extraction are:
- mv-expand
- mv-apply
- evaluate bag_unpack
- extract_json
Others to know save you time down the road, but aren’t necessarily related to extracting nested objects
- tostring
- toint
- todouble
- tolong
- todatetime
- tolower
You want to use this with your extraction so that your field is the proper type so you can use it later. You can’t summarize dynamic types, for instance. Or do date time operations against a string, or even ints, doubles, or longs.
For putting Humpty Dumpty back together after expanding array objects:
- make_set(if)
- make_list(if)
- make_bag(if)
One final note, for the purposes of this blog post.

I understand there’s some hotly contested debate about this, I don’t particularly care. Call them whatever, but in this post those names represent those brackets and braces.
Quick and Dirty Methods
The quick and dirty method still works great for a few columns. I most commonly use this in Azure Resource Graph(ARG). Most often the most important data is buried under the properties field in ARG. To the point that now I pretty much start my queries off with extracting all the relevant fields, even if I might not need them in that specific query. Copy and Paste > typing over and over.
For example, getting Azure Monitor alerts in Azure Resource Graph. The “alertsmanagementresources” table has all fired and resolved alerts for the last 30 days.
alertsmanagementresources
| extend FireTime = todatetime(properties.essentials.startDateTime),
LastModifiedTime = todatetime(properties.essentials.lastModifiedDateTime),
Severity = tostring(properties.essentials.severity),
MonitorCondition = tostring(properties.essentials.monitorCondition),
AlertTarget = tostring(properties.essentials.targetResourceType),
MonitorService = tostring(properties.essentials.monitorService),
ResolvedTime = todatetime(properties.essentials.monitorConditionResolvedDateTime)
This has most the relevant information for alerts, from here you can build summary queries or Workbooks. Notice, every property is cast to a string or datetime. Make a habit of doing this during extraction and save yourself time later.
For this next one, we’ll jump over to Azure Policy, still within ARG. Policy data can be found under the “policyresources” table.
policyresources
| where type =~ 'microsoft.policyinsights/policystates'
| extend resourceId = tolower(properties.resourceId),
resourceType = tostring(properties.resourceType),
policyAssignmentId = tostring(properties.policyAssignmentId),
policyDefinitionId = tostring(properties.policyDefinitionId),
policyDefinitionReferenceId = tostring(properties.policyDefinitionReferenceId),
policyAssignmentScope = tostring(properties.policyAssignmentScope),
complianceState = tostring(properties.complianceState),
assignmentName = tostring(properties.policyAssignmentName)
Notice, for resource id’s I’m using “tolower” on them. While the official guidance is to use tostring because its faster, this doesn’t take into account that resource Ids, can be camel case, and all lower case. Depending on what resource type you’re looking at, the resource id can be different than a reference to the resource id in another column, table, etc . This is especially necessary when joining tables on resource ids. The join will not work if the fields are different cases.
The other quick and dirty method.
This is the exact same query as above(sans some extra columns).
policyresources
| where type =~ 'microsoft.policyinsights/policystates'
| extend resourceId = tostring(properties["resourceId"]),
resourceType = tolower(properties["resourceType"]),
policyAssignmentId = tostring(properties["policyAssignmentId"])
But instead of using dot notation, we can simply call whatever property field we want by throwing it inside quotes inside brackets. Why in the world this works is beyond me. I’ve literally never seen this taught in any of our docs or any KQL stuff I’ve looked at. But there it is in example queries.
It’s not anymore useful than dot notation, until you find you can’t actually reference a property. Over in the resource changes table inside Azure Resource Graph, we have some really useful data. For instance, literally every change or modification that occurs in your azure environment.
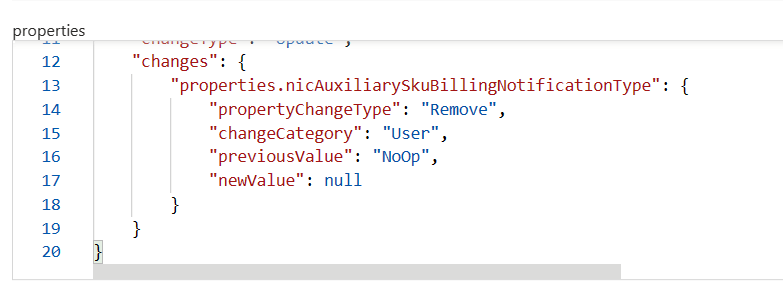
But when you try and reference the change values you get nothing. With this example, one would expect they could reference any of the change properties like this.
resourcechanges | extend test = properties.changes.properties.nicAuxiliarySkuBillingNotificationType
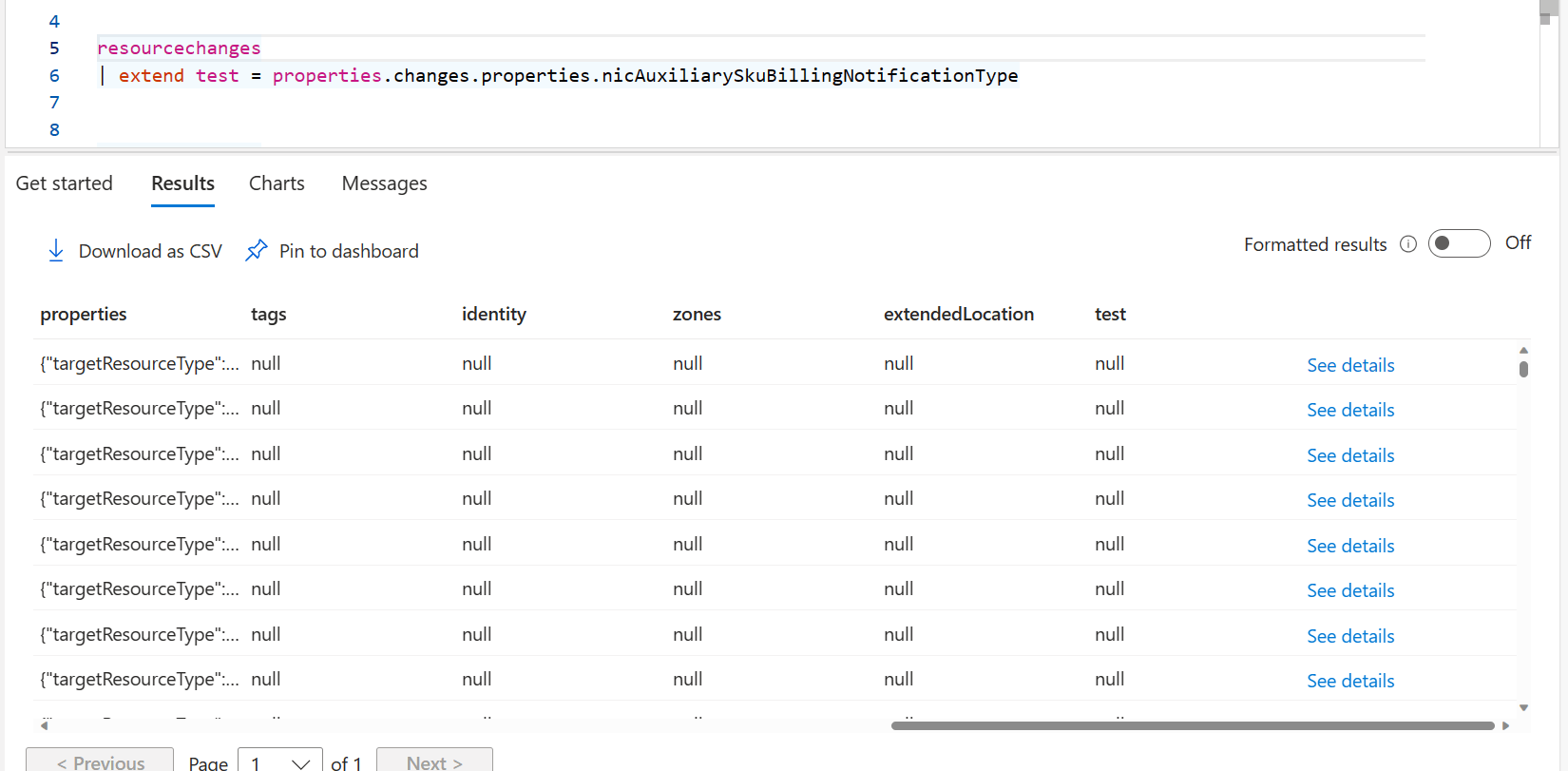
Instead, we get a new column full of nothing.
And no before you ask, mv-expand doesn’t work on these change properties either.
But we can still access them like this.
resourcechanges | extend test = properties.changes["properties.nicAuxiliarySkuBillingNotificationType"]
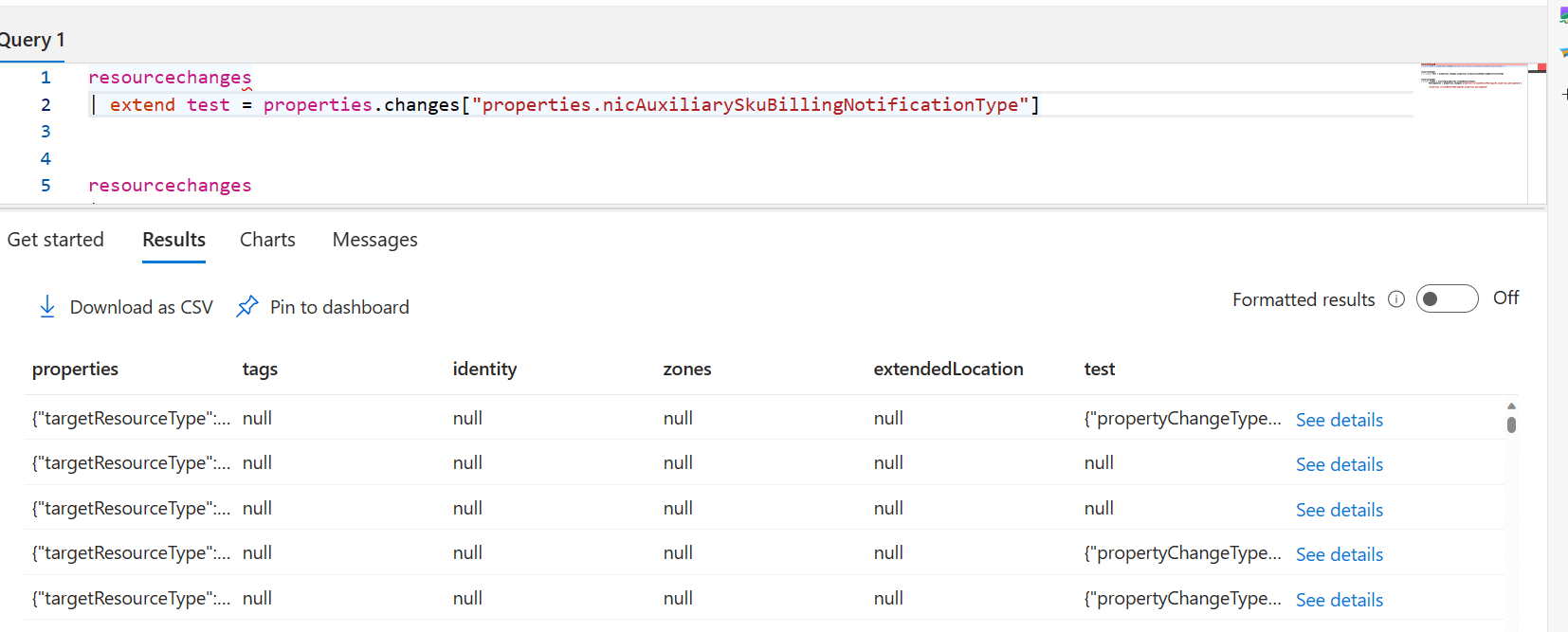
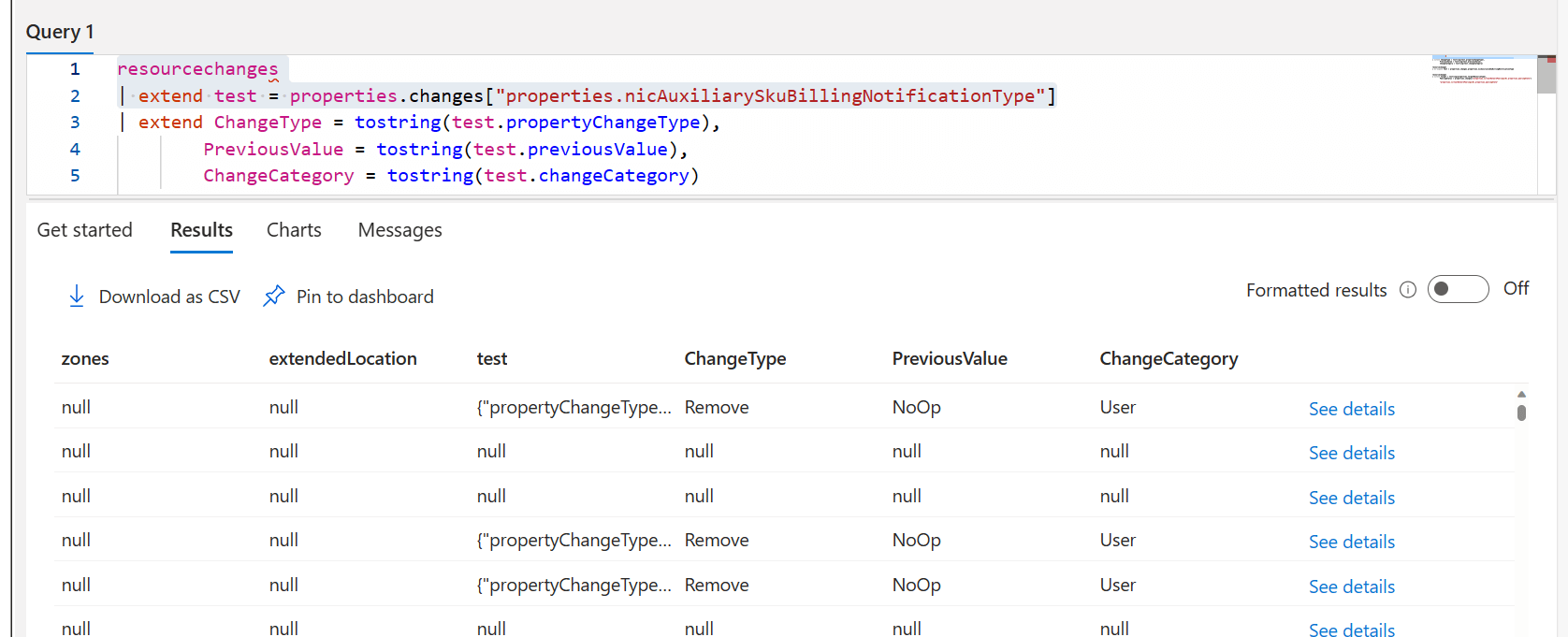
This brings us back another dynamic object that we can now address any property underneath it.
Mv-Expand & Mv-Apply
Up until this point, everything we’ve extracted has been from curly braces {}. However, you will run across fields with: [{}]. Particularly in Azure Resource Graph (ARG) and in Azure AD Logs. Whenever we see brackets, this means we’re dealing with an array object.
Mv-Expand
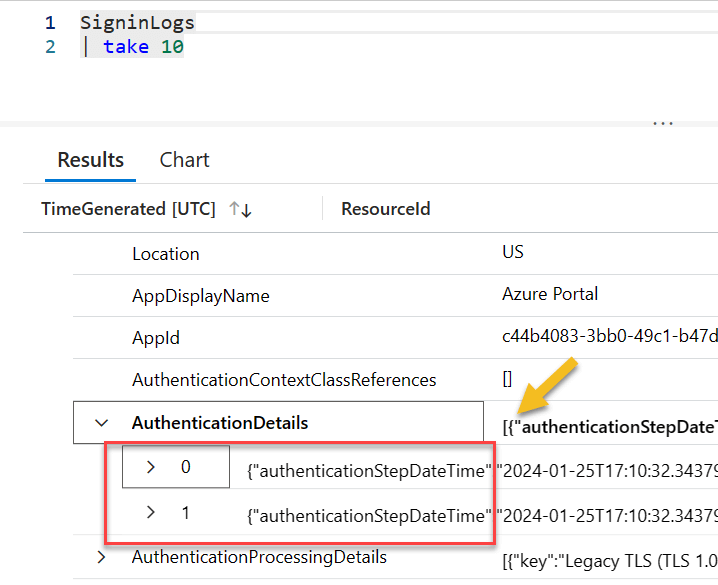
In the AuthenticationDetails column we have an array object, and each item in the array holds a json key value pair. Technically, we can access the objects with something like this: AuthenticationDetails.[0]. This will work, but there is no guarantee that the item you want to extract will be in the same position every time.
The thing to watch out for with mv-expand is you can quickly reach too many records or too large of a dataset. In the first example, I have 6 sign-in logs.
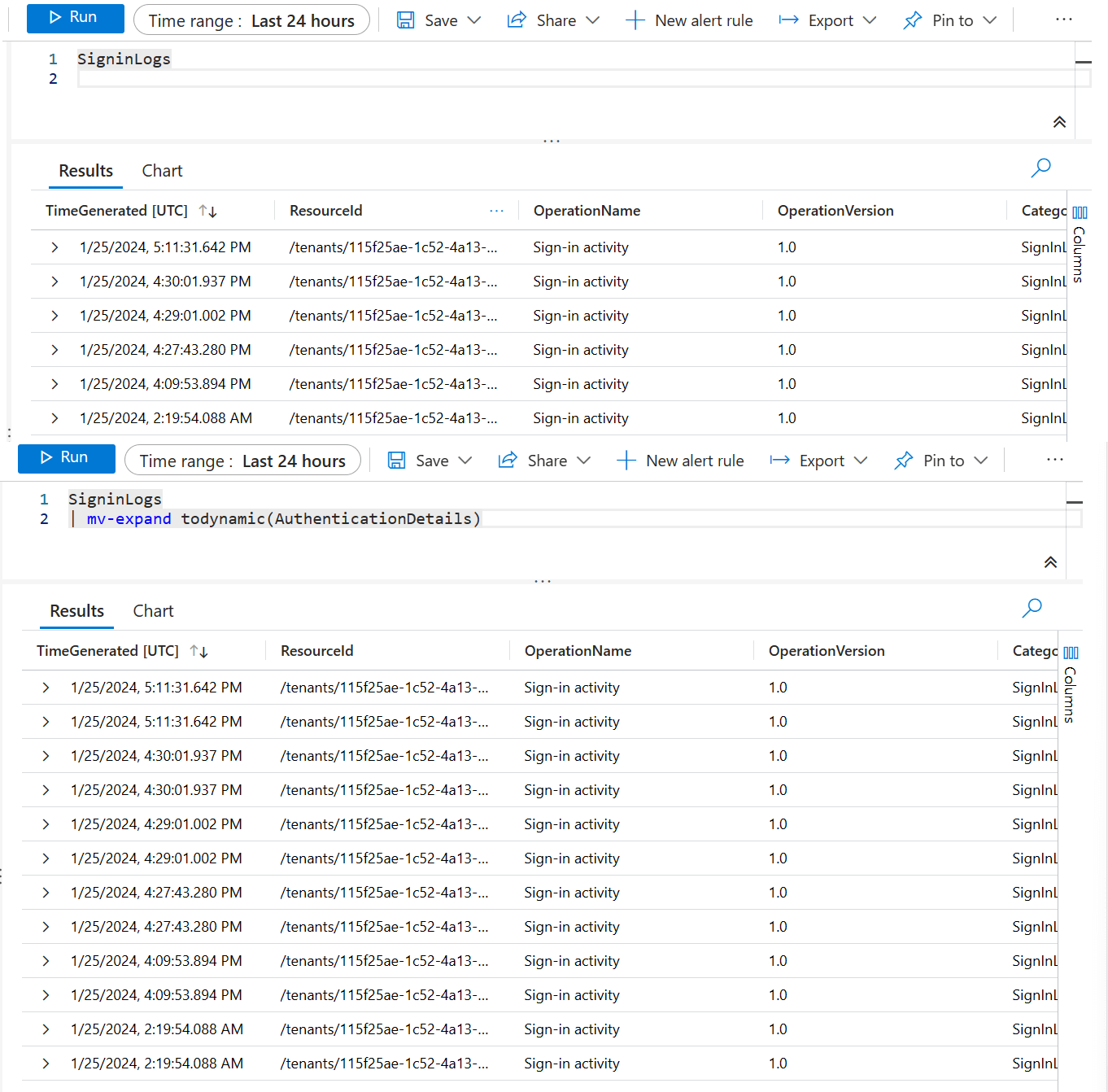
In the second I have doubled the amount of records. You can see how easily it would be to quickly create a much larger dataset. This is what we’ll use mv-apply for, as well as the make set/bag/list aggregation functions for. I’ve got quite a few mv-expand examples on my github and my zero to hero post.
This is one I came up with a few months ago for Data Collection Rules. in DCRs we can have different destinations between Log Analytics and Azure Monitor Metrics etc. However, each destination type is a different property in the JSON object.
We can use coalesce, along with mv-expand to solve this problem.
resources
| where type =~ 'microsoft.insights/datacollectionrules'
| mv-expand Destinations = coalesce(properties.destinations.logAnalytics,
properties.destinations.monitoringAccounts,
properties.destinations.azureMonitorMetrics)
| extend Destinations = tostring(case(isnotempty(Destinations.workspaceId), Destinations.workspaceResourceId,
isnotempty(Destinations.accountResourceId), Destinations.accountResourceId,
Destinations.name == "azureMonitorMetrics-default", "Azure Monitor Metrics", "unknown")),
id = tolower(id)
| project id, Destinations
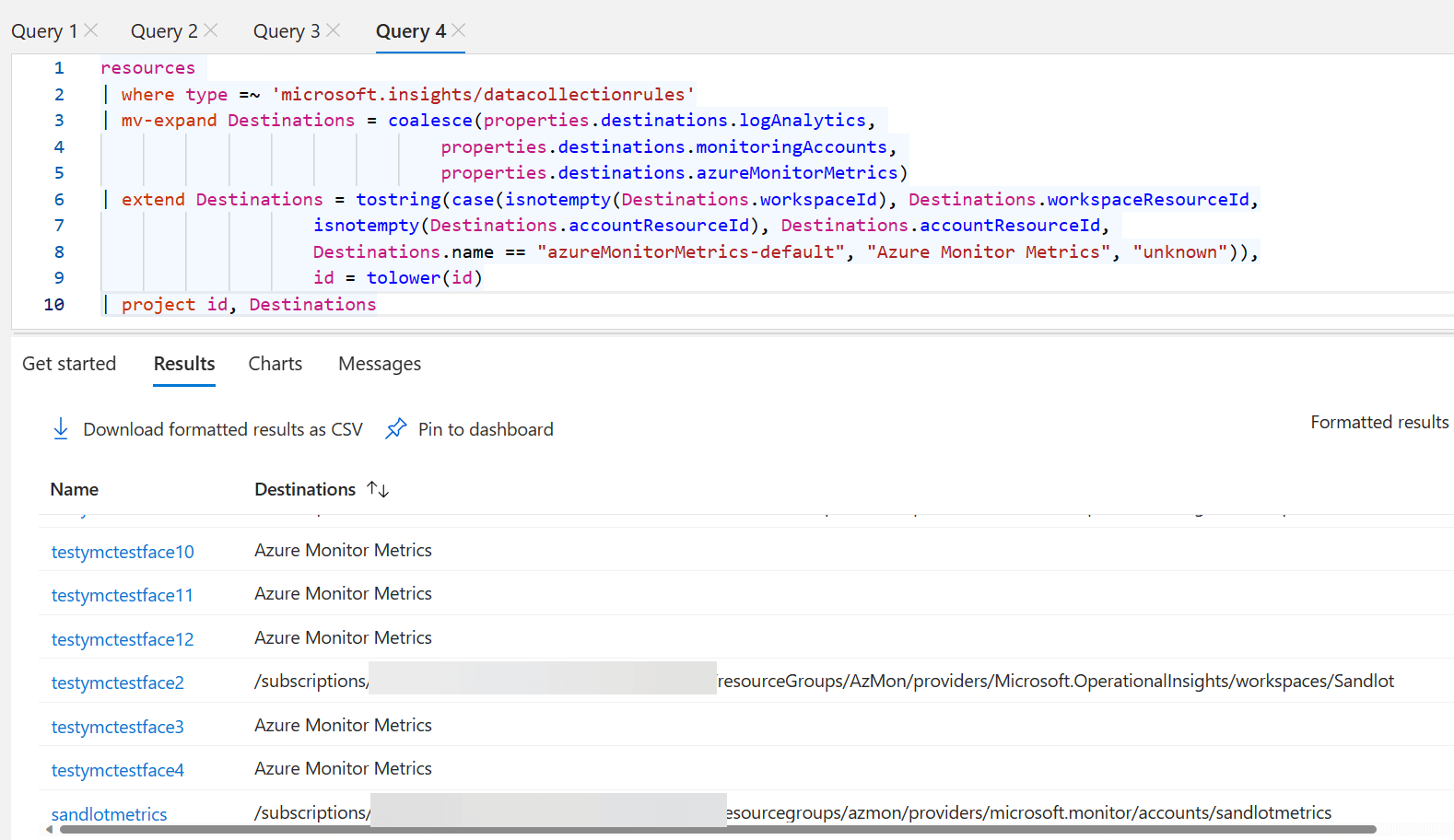
From there we use tostring and case statement to get either resource ID or human readable text.
What if we want to get a list of VMs assigned to a specific DCR as well as their destinations? This is multiple 1 to many relationships, as a DCR can be assigned to thousands of VMs, and a DCR can have multiple destinations. We can use make_set to make this more manageable. Make_set makes a unique, list of objects from the column you provide. Make_list includes duplicate entries.
resources
| where type =~ 'microsoft.insights/datacollectionrules'
| mv-expand Destinations = coalesce(properties.destinations.logAnalytics,
properties.destinations.monitoringAccounts,
properties.destinations.azureMonitorMetrics)
| extend Destinations = tostring(case(
isnotempty(Destinations.workspaceId), Destinations.workspaceResourceId,
isnotempty(Destinations.accountResourceId), Destinations.accountResourceId,
Destinations.name == "azureMonitorMetrics-default", "Azure Monitor Metrics", "unknown")),
dcrId = tolower(id)
| join kind = leftouter(
insightsresources
| extend id = tolower(id)
| parse id with resourceId "/providers/microsoft.insights/" *
| extend resourceId = tolower(resourceId), dcrId = tolower(properties.dataCollectionRuleId)
| summarize AssignedVMs = make_set(resourceId) by dcrId ) on dcrId
| project dcrId, Destinations, subscriptionId, resourceGroup, AssignedVMs
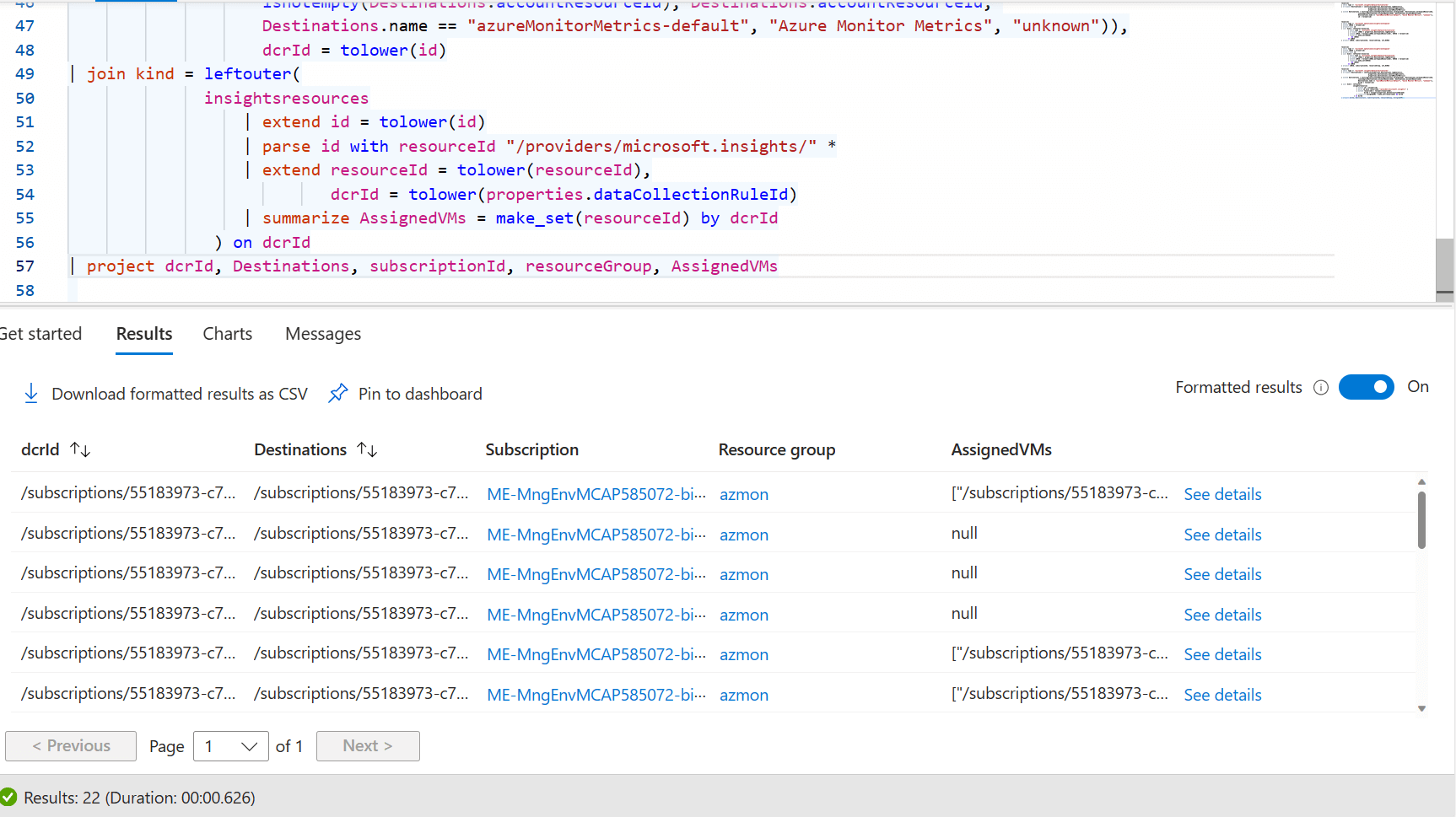
Using make_set on the VMs gets us back down to our original 22 Data Collection Rules.
Mv-Apply
Up to this point, we expanded all objects in the array. But what if we only want 1 or 2 items out of the entire array? Mv-Apply to the rescue. My colleague Matt Zorich enlightened a group of us to this function. He has a post of his own here, that you can read.
Mv-Apply is a godsend for Windows Event Log. Sometimes there is data we want that isn’t in the rendered description, or any other column. A while back I got pinged by someone with help extracting XML from the Event Log.
How my reaction went from help with KQL to help with XML in KQL.

Parse_XML and Mv-Apply to the rescue.
First lets look at the difference between the XML column and the Parsed XML column.
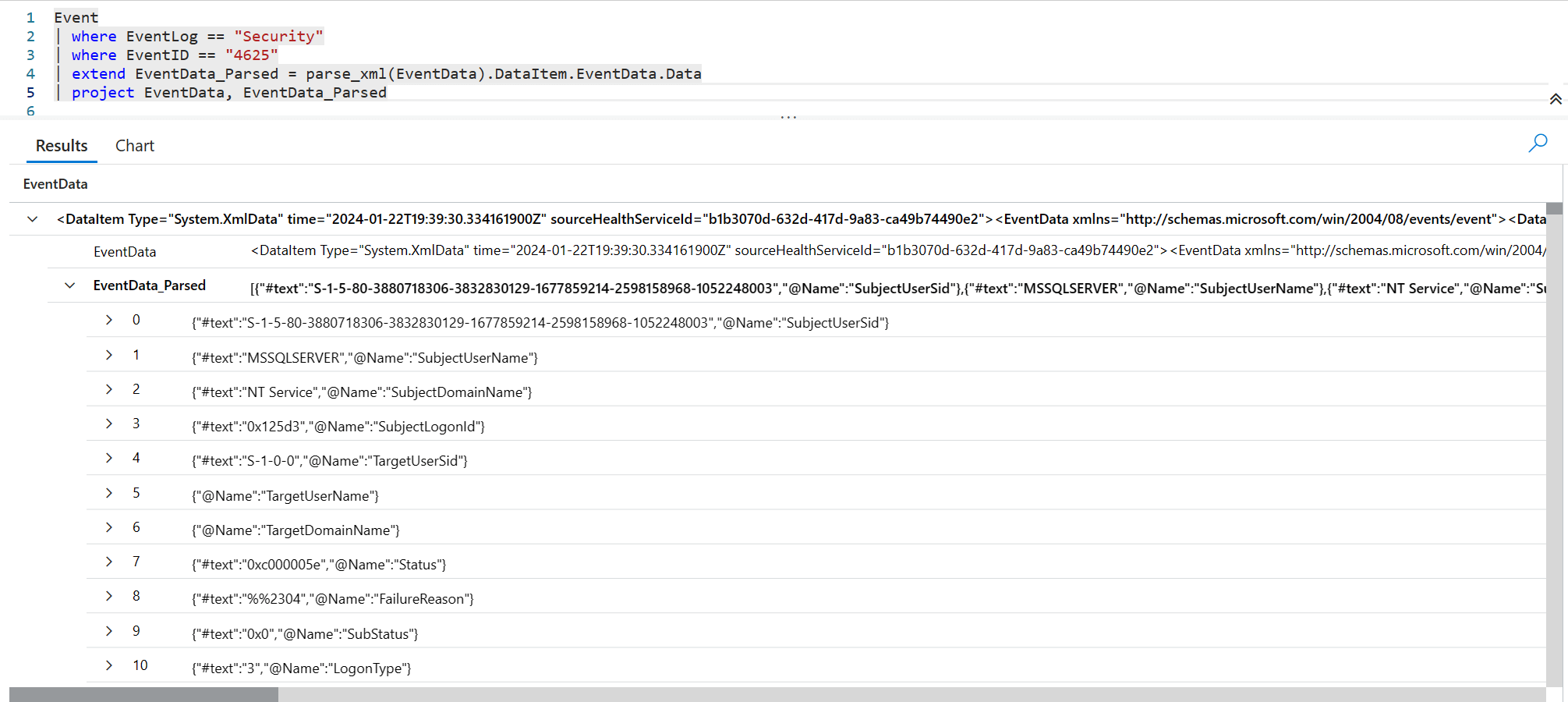
Parse_XML converted the XML to nested JSON key value pairs. From here we add Mv-Apply to get any data we want.
Event
| where EventLog == "Security"
| where EventID == "4625"
| mv-apply EventData = parse_xml(EventData).DataItem.EventData.Data on(
where EventData['@Name'] == 'Status'
| project Status = tostring(EventData['#text'])
)
| summarize TotalFailures=count() by Status, Computer
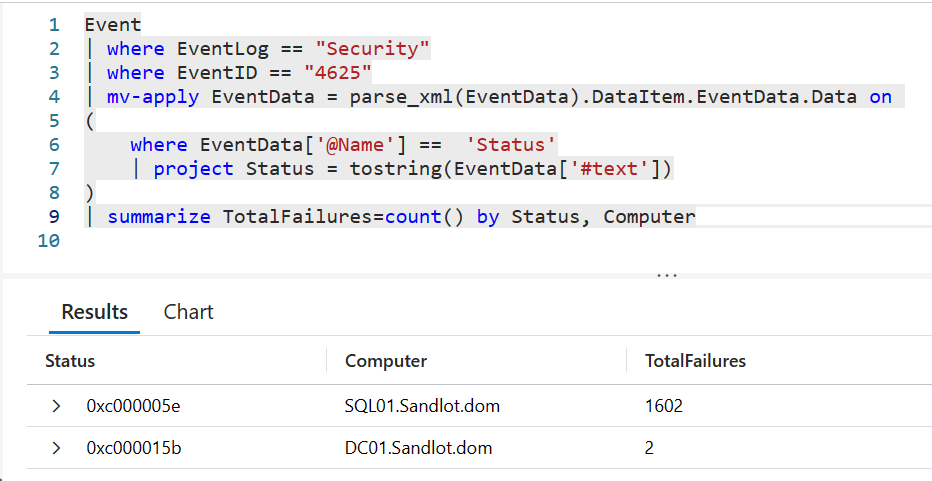
The way Mv-Apply works is that it allows you to filter inside the array by some property. You can create new fields with project and extend, or even summarize data from inside the Mv-Apply.
Another example my colleague Graeme Bray used to get Windows Time Service issues. This one uses Parse_XML, Mv-Apply, bag_pack, make_bag, and evaluate bag_unpack.
Event | extend EventData=parse_xml(EventData) | project TimeGenerated, SourceSystem, Source, EventLog, EventData = EventData.DataItem.EventData.Data | where Source == "Microsoft-Windows-Time-Service" | mv-apply EventData on ( project entry=bag_pack(tostring(EventData["@Name"]), tostring(EventData["#text"])) | summarize make_bag(entry)) | evaluate bag_unpack(bag_entry,"data")
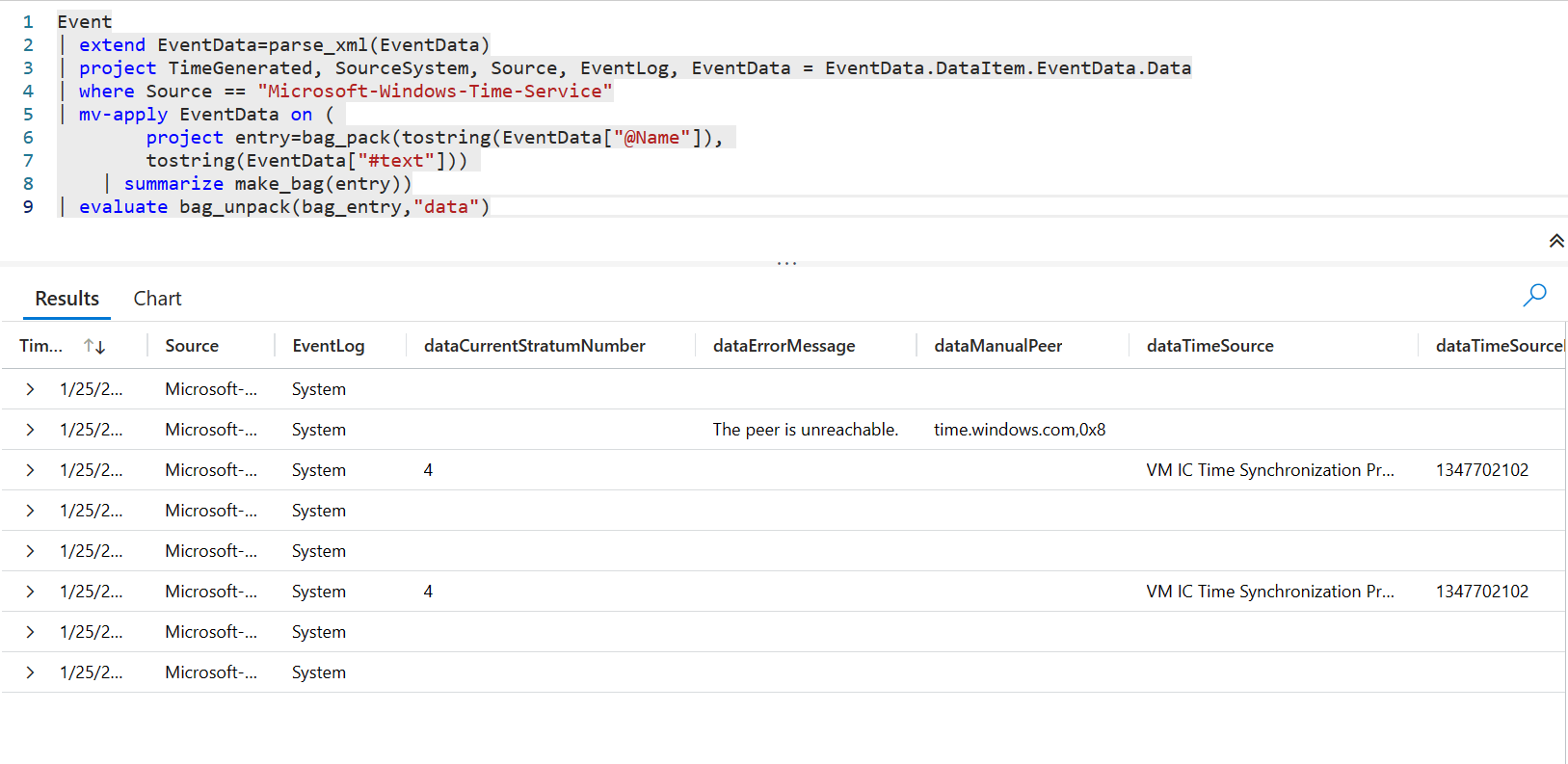
Evaluate bag_unpack will unpack all objects of your JSON and make them new columns, which is kind of neat. You can also handle conflicts with existing column names, or add a prefix to the column names.
Extract_JSON
This one wasn’t even originally planned to be part of this post. But Graeme came saying nothing he tried could get this data out of some Microsoft Defender logs.
The data he wanted was under AdditionalFields -> Metadata -> MachineEnrichmentInfo
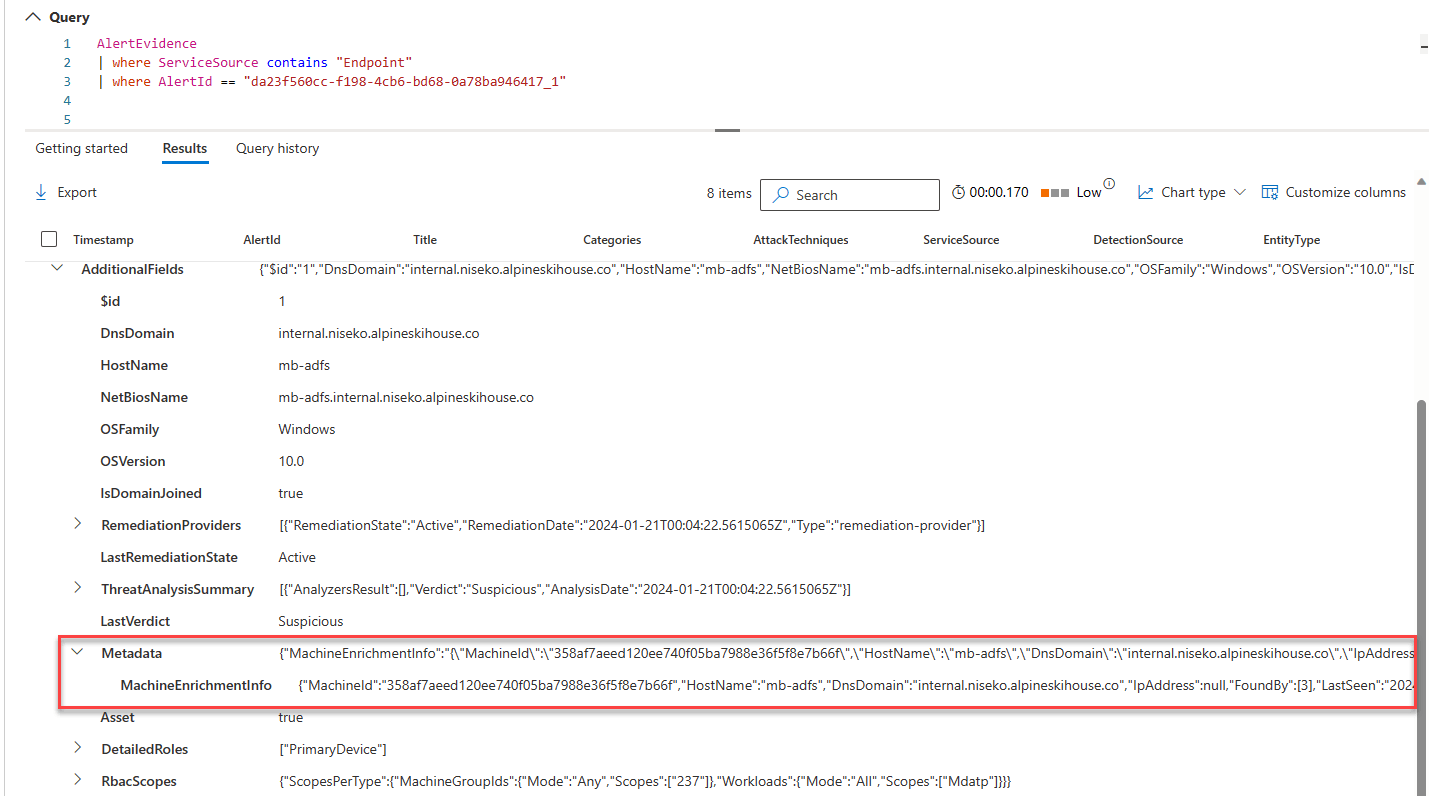
I tried literally every method mentioned above. Nothing worked.
The data he wanted was in a column called MachineTagsJson.
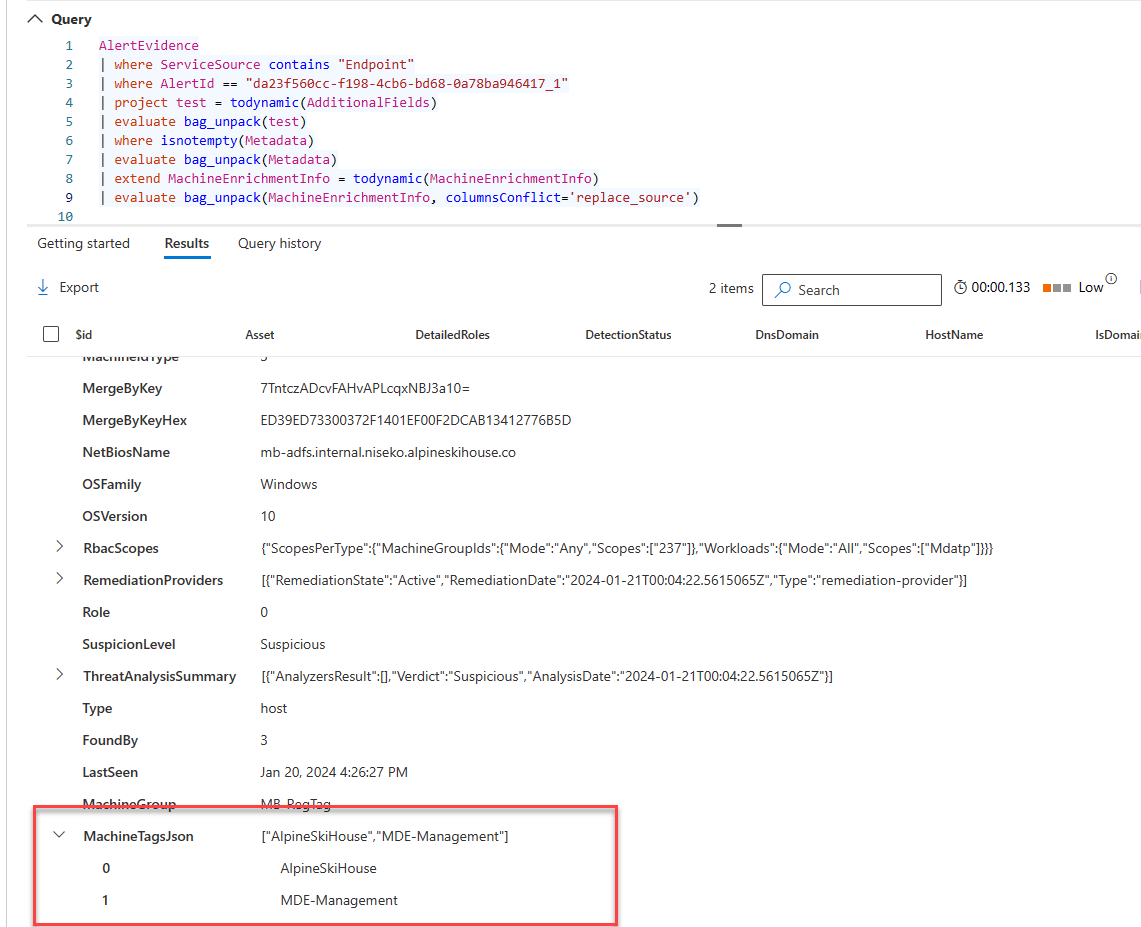
This is a ridiculous query, don’t use it. But I wanted to show how absurd it was to get this data. Again I tried the other quick and dirty method above, mv-expand, evaluate bag_unpack. BUT! The field was now addressable. I sat there saying there has to be a better way. Some web searching later, I stumbled upon the extractjson function. It takes a json path, your column name, and object type.
This query worked.
AlertEvidence
| where ServiceSource contains "Endpoint"
| where AlertId == "da23f560cc-f198-4cb6-bd68-0a78ba946417_1"
| extend test = extractjson("$.Metadata.MachineEnrichmentInfo", AdditionalFields, typeof(string))
| extend Tags = extractjson("$.MachineTagsJson", test, typeof(string))
Voila! MachineTagsJson addressable.
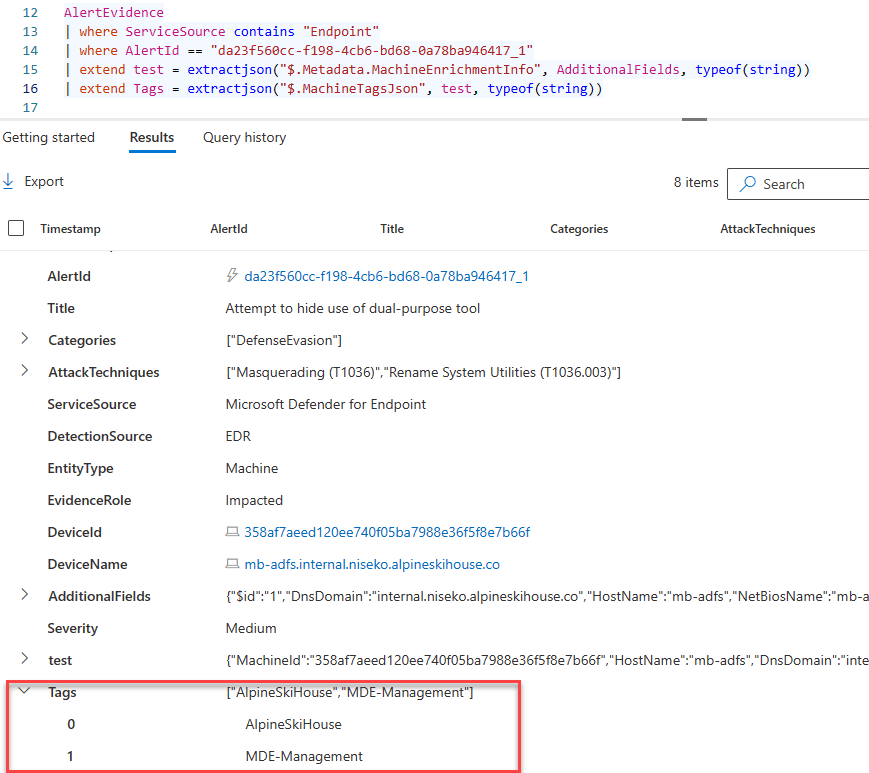
Whats interesting, is that I could not do:
extractjson(“$.Metadata.MachineEnrichmentInfo.MachineTagsJson”, AdditionalFields, typeof(string))
That didnt work, so I had to do a second line with another extractjson.
Conclusion
