
The evaluate operator is fantastic tool in your Kusto tool belt. So much so that I have requested several times that it get added to Azure Resource Graph. However, the Evaluate Operator itself won’t run anything. You have to add one of its Plugins behind it. In this post I’ll show you how to use some of the plugins and what I find them useful for.
Evaluate Pivot
Pivot is a pretty self explanatory plugin. It pivots two arguments that you give it. The first field pivots and makes a column and the second goes under the first field. For instance if you pivot drives on a computer by Instance name and value, it will move C: and any other drive letter and make it a column. The catch, though is you have to give it an aggregation function. That’s right, Evaluate Pivot acts like summarize. However, unlike summarize, you can only do one aggregation function at a time.
That said you can easily get the average, or any other aggregation function, of all drive instances against all LogicalDisk counters with this two line query. And any new CounterName you add, would automatically get added to this query. Pretty neat, I think.
Perf | where ObjectName == 'LogicalDisk' | evaluate pivot(InstanceName, avg(CounterValue))

Evaluate Bag_Unpack
Bag unpack is one of my absolute favorites. I’ve blogged about it previously, there are a number of ways to extract nested fields, from parse_json, to mvexpand, but bag_unpack does the best job to me.
Just look at this mess of a field in the Azure Activity log for Claims.
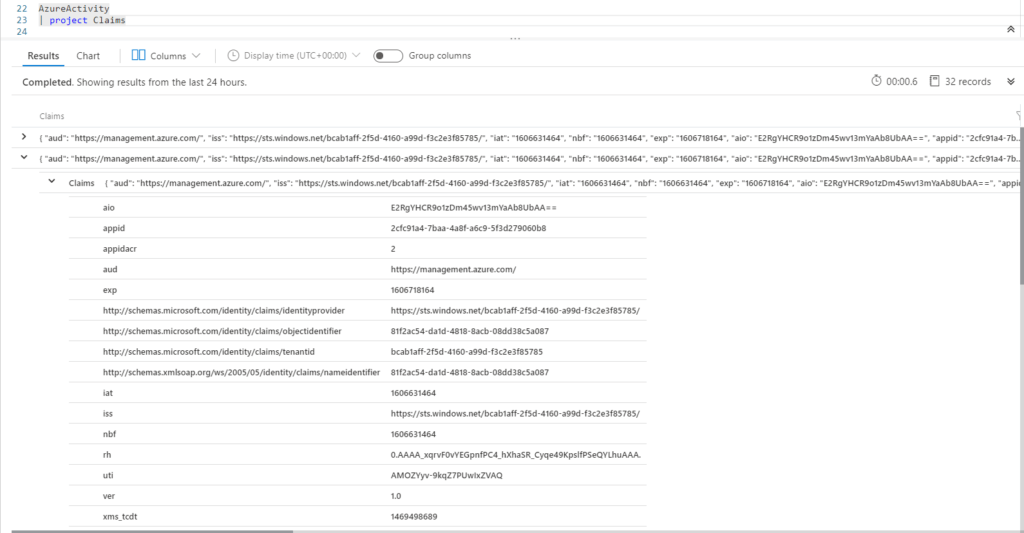
Then we make Claims a dynamic field and throw it in evaluate bag_unpack and viola all new fields automatically. It will do all of them, no matter how many there are in your nested field.
AzureActivity | project todynamic(Claims) | evaluate bag_unpack(Claims)
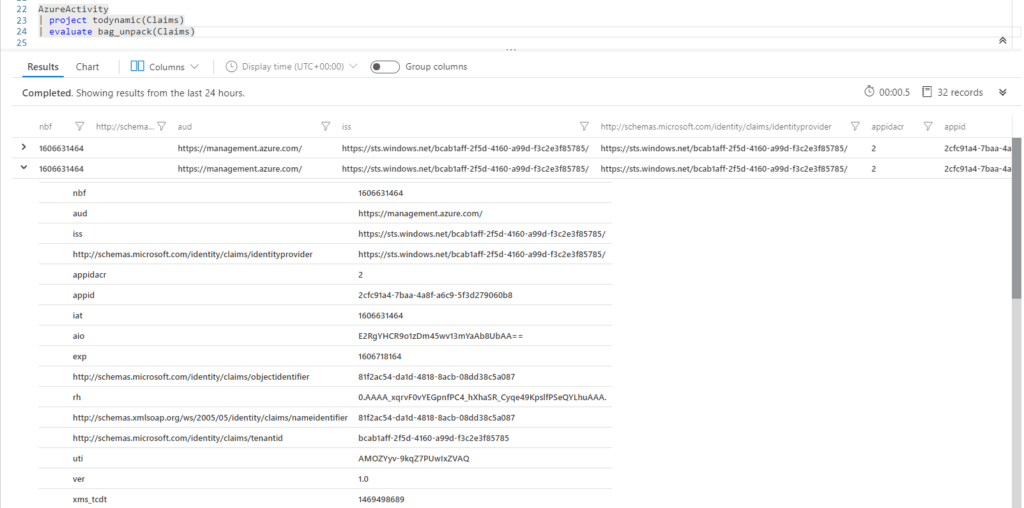
Every field under Claims has become its own column. Neither mvexpand or parse_json can pull this off without adding extra commands. And this is the precise reason I prefer bag_unpack. More often than not these nested fields have data changing from log to log, so using the quick and dirty method or mvexpand or parse_json under the main nested field will be inconsistent.
Evaluate Narrow
Narrow is a nice plugin I’ve most commonly used in my Azure Monitor workbooks, like my WVD workbook or my Change Tracking workbook. Narrow takes no arguments, but will take your data and put it under 3 columns; Row, Column, and Value.
Take this query from my Change Tracking workbook
ConfigurationData | summarize Publishers=dcount(Publisher), Software=dcount(SoftwareName)
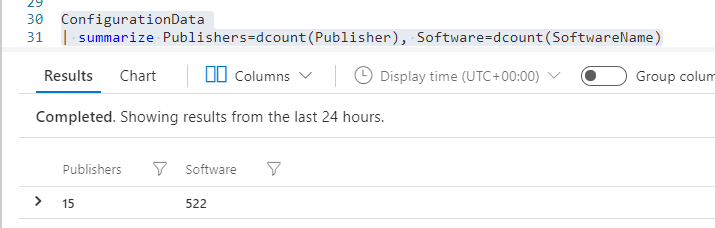
We have two fields, Publishers and Software. In this instance I wanted to put each of these in tiles in my workbook.
However, the title field or any field in the workbook wants 1 field to have everything under. So I can do Publishers and not Software, or I can do Software and not Publishers.
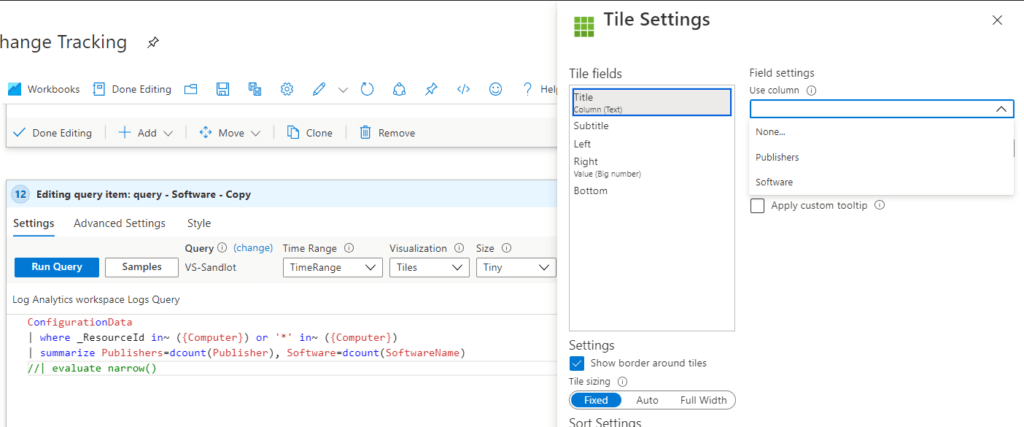
ConfigurationData | summarize Publishers=dcount(Publisher), Software=dcount(SoftwareName) | evaluate narrow()
Add evaluate narrow() to the end and now we can select Column for our Title and put Value under right.
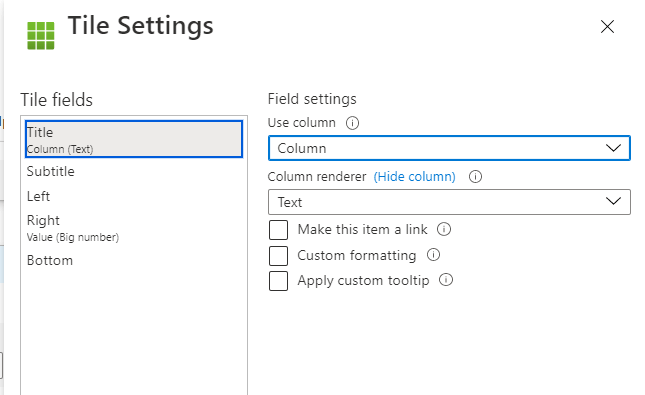
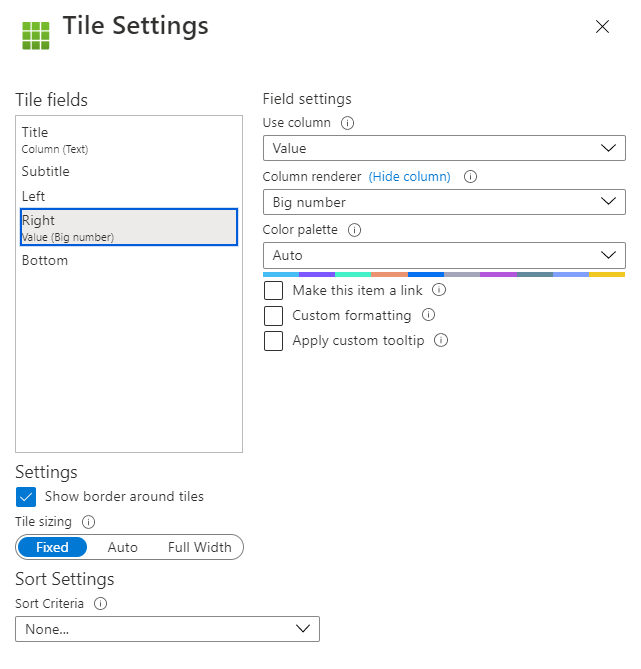
And now we have the result that we want. Tiles with Publishers and Software as the title.
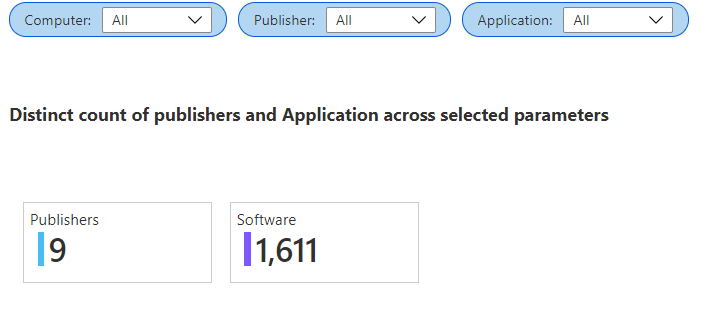
In certain instances you can use Narrow and then Pivot. But this was for a very complicated data set.
Evaluate Autocluster and Basket
Some wildcards you want to be aware of that offer a little flavor of machine learning in Log Analytics is Evaluate Autocluster and Evaluate Basket. These are both useful for catching anomalies in your logs. At this time I don’t have any good demo material, but maybe I’ll add a machine learning post for the future.